Home »
La vision humaine comprend des ondes électromagnétiques d’une longueur d’entre 400 et 700 nanomètres. En partant des 700nm en direction des 400 nm, nous avons les couleurs de l’arc en ciel : le rouge @ 600-700nm et le violet @ 400nm, avec l’orange, le jaune, le vert et le bleu entre les deux. La réponse humaine optimale par rapport à la lumière se situe vers les 550 nm, soit au milieu de la bande verte, dont l’illustration se trouve dans cette courbe de réponse :
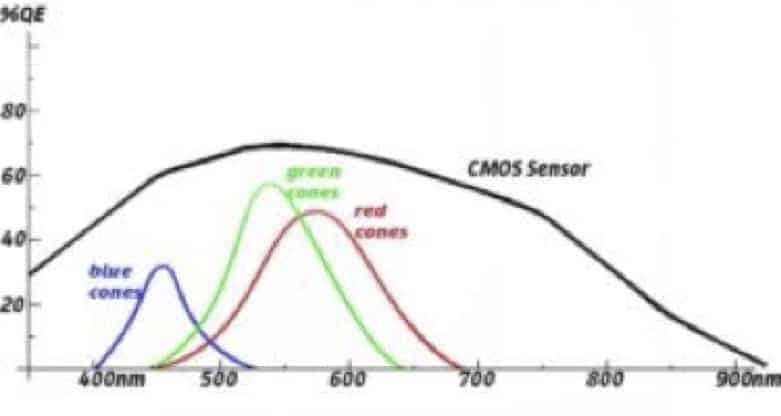
Vous remarquerez les courbes pour le rouge, le vert et le bleu. Ces trois types de photorécepteurs nous donnent la possibilité de percevoir jusqu’à environ 10.000.000 teintes, même si certains d’entre nous ont une acuité beaucoup plus marquée que d’autres. La disparité est beaucoup plus grande chez les animaux. Certains ont jusqu’à 15 photorécepteurs différents, généralement pour des bandes étroites très spécialisées, alors que d’autres sont considérés comme daltoniens.
Les capteurs CMOS, utilisés pour la plupart des caméras numériques, sont sensibles à une bande plus large que les humains et la plupart des animaux, soit en général de 300 nm à 900 nm, représentés par le trait noir sur la courbe de réponse ci-dessus.
Cette divergence de réponse entre les capteurs de caméra et la vue humaine et animale, présente des opportunités ainsi que des problématiques.
L’opportunité majeure réside en l’utilisation des caméras monochromes avec un éclairage proche de l’infra-rouge (Near Infra-Red, ou NIR) pour des applications qui demande un éclairage intense sans déranger les sujets test. Bien des études de poissons zèbres, de chauves-souris et de certains insectes se pratiquent via cette technique, puisque ces animaux ne sont pas sensibles au NIR.
Plus problématique est la reproduction de la couleur par la caméra. Ce processus se résume à trois étapes :
- Un filtre, qui sert à éliminer la lumière qui dépasse le spectre visible, est placé entre l’objectif et le capteur. En général il s’agit d’un filtre anti-IR, qui limite la lumière au-delà de 650 nm. Malgré une lumière conséquente dans cette bande, cette étape est nécessaire parce les humains ne la perçoivent pas. Nous ne devons donc pas l’utiliser si nous cherchons à répliquer la perception humaine. Un exemple serait certains feuillages, qui reflètent une quantité importante de NIR. Sans filtre anti-IR un arbre d’un vert sombre pourrait paraître en rouge vif dans la caméra !

- Une matrice Bayer s’applique aux capteurs couleur. Ce filtre, qui est une matrice de filtres colorés, consiste à poser un filtre rouge, vert ou bleu par dessus chaque pixel du capteur. Ils sont positionnés dans des lignes vert/bleu/vert et rouge/vert/rouge, de manière à ce que la moitié de tous les pixels soient verts, un quart en soient rouges et un quart bleus. De cette façon, chaque pixel ne réagit qu’à la bande de lumière qui correspond approximativement à ce qui serait visible par les courbes rouges, verts et bleus de l’œil humain.
- L’interpolation de la couleur se fait pixel par pixel, afin de rendre les valeurs rouge, vert et bleu pour chacun d’entre eux. Pour chaque pixel individuel, sa valeur est associée à celle des pixels avoisinants pour donner ces valeurs “RGB” (rouge/vert/bleu).
Certaines caméras utilisent des capteurs multiples, chacun possédant sa propre filtration couleur, afin de créer de la couleur. Certains capteurs ont la possibilité de recevoir des données RGB par pixel. Mais la plupart des caméras numériques couleur utilisent les techniques ci-dessus. Il y a quelques inconvénients évidents à utiliser des caméras couleur plutôt que monochromes :
- Presque la moitié de la lumière à laquelle le capteur est sensible, est éliminée par le filtre anti-NIR. Ensuite, pour chaque pixel, une grande partie de la lumière résiduelle, en dehors de sa propre bande de couleur, est également éliminée. Par conséquent, les caméras ont 50% de la sensibilité des caméras monochromes, selon le spectre d’éclairage.
- Les algorithmes d’interpolation sont optimisés pour la lumière naturelle. Il existe de l’éclairage de qualité pour reproduire la lumière blanche et la lumière de jour, mais il est souvent problématique d’obtenir un rendu des couleurs fidèle avec la plupart des éclairages artificiels.
- Afin d’obtenir des valeurs RGB pour chaque pixel, il est nécessaire d’utiliser les pixels environnants, ce qui veut dire que la résolution spatiale pour la caméra couleur n’est pas aussi fine que celle d’une caméra mono. Ceci ne veut pas dire qu’il est impossible d’avoir des images extrêmement nettes en couleur, mais les images mono sont en général encore plus nettes.
Des bords à haut contraste ne fournissent pas d’informations suffisamment détaillées sur les couleurs pour les besoins des algorithmes d’interpolation, avec comme résultat du repliement de couleurs. Par exemple, vous verrez souvent des traces de rouge, de vert et de bleu sur des images de texte en noir et blanc.
La plupart des caméras sont déclenchées au moment où il faut capturer une image. Par exemple, avec un appareil photo, une fois la prise de vue composée, le photographe attend le bon moment et déclenche l’appareil en appuyant sur le bouton d’obturateur ou sur un déclencheur à distance. Pour une caméra vidéo, un signal de déclenchement (« trigger ») est envoyé pour démarrer l’enregistrement, et un deuxième pour le terminer.
Cependant, les événements à haute vitesse peuvent se produire trop rapidement pour que le photographe puisse réagir à temps. Une stratégie pour permettre de capter un événement à haute vitesse consiste à démarrer l’enregistrement bien avant l’événement attendu, et à poursuivre jusqu’à ce qu’il se soit produit. Le problème avec cette stratégie vient du débit élevé d’images, car le volume d’images vidéo peut être très conséquent. Il peut manquer de la mémoire pour tout capturer, ou bien les données à analyser peuvent être démesurées.
La méthode la plus courante pour traiter la problématique du déclenchement avec une caméra rapide est par l’utilisation d’un tampon (buffer) circulaire et d’un « trigger de fin ». Le tampon circulaire est paramétré de manière à filmer pendant une certaine durée, qui se chiffre habituellement en secondes, même si des séquences plus longues sont possibles avec un SSD. Le tampon enregistre un laps de temps prédéfini, puis écrit par-dessus les images les plus anciennes, tout en conservant les plus récentes. Par exemple, le tampon pourrait enregistrer pendant 10 secondes avant de recommencer au début. Lorsque la caméra reçoit le signal de fin, elle arrête d’enregistrer. Si un trigger peut être envoyé dans les 10 secondes qui suivent l’événement, il sera capté.
Souvent, les images qui précèdent et qui suivent l’événement peuvent s’avérer utiles. Dans ce cas, il est possible de positionner le trigger où nous le souhaitons dans le buffer. Avec l’exemple ci-dessus, et avec un déclenchement programmé à 50% du buffer, nous enregistrerions toujours 5 secondes avant et 5 secondes après le déclenchement.
La durée d’enregistrement avec une caméra rapide dépend de la résolution et de la vitesse d’image sélectionnées, ainsi que de l’espace de stockage disponible.
Les caméras rapides de chez Fastec Imaging peuvent enregistrer soit sur de la RAM haute vitesse soit sur un disque SSD haute vitesse. Veuillez consulter les fiches techniques des différents produits pour connaître les temps d’enregistrement des caméras rapides Fastec. Un calcul approximatif simple pour le temps d’enregistrement serait :
Espace de stockage / [(Résolution horizontale) X (Résolution verticale) X (profondeur de bits) X (vitesse d’image)]
Quelques avertissements cependant :
Certains supports de stockage ne gèrent pas toute la bande passante de la caméra.
Quelques métadonnées sont sauvegardées avec chaque fichier. Elles sont négligeables pour les images en mégapixels, mais plus la taille de fichier se réduit, plus les métadonnées deviennent un facteur important.
Lorsqu’il s’agit d’un système de caméra numérique, nous pouvons définir l’exposition en termes de quantité de lumière utilisée pour chaque image. Trois facteurs ont une incidence sur l’exposition :
- L’éclairage, soit la source de lumière qui est projetée sur le capteur, reflétée par l’objet à imager, ou émise par celui-ci
- La transmittance de l’objectif, qui se contrôle via son ouverture
- L’intégration ou le temps d’obturation de la caméra, soit le temps pendant lequel le capteur recueille effectivement de la lumière pour chaque image.
L’exposition idéale pour un capteur dépend de sa photosensibilité, qui est constante pour un niveau de gain donné. En général, la qualité d’image, surtout par rapport au bruit et à la plage dynamique, se dégrade au fur et à mesure que le niveau de gain augmente.
Des arbitrages sont également à faire sur les facteurs ayant une incidence sur l’exposition :
- Un rajout ou un ajustement de l’éclairage est souvent nécessaire pour obtenir les meilleures images. Cela est devenu un art pour la photographie ou la cinématographie professionnelle. L’équilibre à trouver ici est celui de l’effort. L’éclairage adéquat d’une scène peut-être une tâche fastidieuse, pour laquelle le temps ou la volonté peuvent manquer. Il existe de nombreuses situations où le rajout du complément lumineux nécessaire à une exposition idéale est impossible.
- Ajuster le diaphragme aura une incidence sur la profondeur de champ, soit la distance/profondeur sur laquelle les objets sont nets. La profondeur de champ augmente au fur et à mesure que le diaphragme ferme, afin de transmettre moins de lumière, et ceci s’avère utile en général pour les images à haute vitesse. À l’inverse, plus l’ouverture est grande, moins importante sera la profondeur de champ.
- Ajuster la durée d’obturation aura une incidence sur l’exposition. L’exposition maximale pour une fréquence d’image donnée est un intervalle d’un peu moins de 1/fréquence d’image. Lors de la prise de vue d’objets qui traversent rapidement le champ de vision, il est souvent nécessaire de réduire la durée d’obturation afin de minimiser le flou de mouvement. Le niveau tolérable de flou dans une situation donnée dépendra de la forme de l’objet à imager, ainsi que de la netteté requise pour l’analyse de son comportement.
Avec une caméra standard, nous nous attendons à ce que le mouvement à travers le champ de vision soit légèrement flou, ce qui permet un rendu réaliste à l’écran. Après tout, une image animée n’est autre qu’une série d’images fixes, projetées suffisamment rapidement pour tromper l’œil.
Le terme « angle d’ouverture » s’utilise souvent avec les caméras pour décrire les paramètres d’obturation, un vestige de l’époque où l’obturateur était un disque tournant, et synchronisé de sorte à faire une rotation de 360° entre chaque image. L’opérateur devait choisir l’angle d’ouverture pour l’exposition de la pellicule. La valeur habituelle était de 180°, pour donner un temps d’ouverture correspondant à la moitié de l’intervalle du débit d’image. C’est cette valeur qui permettait l’aspect le plus naturel, alors que des valeurs plus faibles permettaient de rajouter de l’intensité au mouvement dans les scènes d’action.
Pour les besoins de l’analyse d’un mouvement, par contre, il vaut mieux une image nette et sans distorsion pour permettre un examen image par image. Dans ce cas, le temps d’exposition doit souvent être assez court afin de s’assurer que l’objet cible n’ait pas le temps de bouger, évitant ainsi un flou de mouvement.
Vous pouvez calculer le flou de mouvement si vous connaissez la vitesse à laquelle l’objet se déplace, les dimensions du champ de vision, la résolution des pixels, et le temps d’ouverture. La fréquence d’image n’a pas d’importance. Par exemple, si une voiture avance à 30 mph à travers un champ de vision d’une largeur de 50 pieds, avec une résolution horizontale de 1920 pixels et une vitesse d’obturation de 100 microsecondes :
Nous pouvons calculer la distance parcourue par la voiture pendant les 100 ms,
• 30 mph = 44 pieds/sec. 100 ms = 0,0001 secondes, la voiture avance de 0,0044 pieds en 100 ms
ensuite, la distance par rapport au champ de vision (50 pieds)
• 0,0044/50 = 0,00088
et enfin à combien des 1920 pixels horizontaux de l’image cela correspond :
• 0,00088 x 1920 = 1,68
Le flou de mouvement, mesuré en pixels, est d’environ 2 pixels. Ce chiffre est directement proportionnel à la durée de l’ouverture. Ainsi, une ouverture d’une milliseconde donnerait 16,8 pixels de flou. Le niveau acceptable de flou dépendra de la taille et de la complexité de l’objet à étudier, ainsi que de l’exactitude requise.
L’image IL5 en bas à droite, d’un ventilateur 4 pouces, 50 Hz, a été réalisée avec une ouverture de 60 ms. Le flou de mouvement est extrêmement réduit par rapport à l’image de l’iPhone à gauche.

Image fixe d’un ventilateur, réalisée avec un iPhone – les pales semblent floues

La même image fixe, réalisée avec la Fastec IL5, obturation de 60 microsondes
La plupart des caméras numériques rapides comportent un obturateur global électronique, où ‘global’ désigne une conception par laquelle tous les pixels démarrent et terminent ensemble leurs fonctions lumière/charge. C’est une opération très spécialisée qui, avec d’autres aspects, constitue une différence notable entre les « vraies » caméras rapides et les caméras vidéo standards avec ralenti. Cela demande une conception de pixels plus complexe dans laquelle, dès l’intégration (exposition), la charge de chaque pixel est passée à une structure non-photosensible à l’intérieur du pixel, où elle est stockée jusqu’à sa lecture, libérant ainsi le pixel, qui peut commencer à intégrer l’image suivante.
La plupart des caméras numériques utilisent un obturateur électronique « roulant », avec lequel les pixels sont lus dès l’exposition, mais ne le sont pas tous simultanément. Ceci veut dire que la durée réelle d’exposition n’est pas la même pour toute l’image, et qu’un mouvement éventuel pendant la lecture du capteur pourrait se révéler progressivement dans chaque image.
Image fixe d’un ventilateur, réalisée avec un iPhone – les pales semblent floues
La même image fixe, réalisée avec la Fastec IL5, obturation de 60 microsondes
La comparaison classique entre obturateur global et obturateur roulant se fait avec des images de pales de ventilateur, où les pales semblent se déplacer vers un côté du ventilateur. L’image de gauche a été réalisée avec un iPhone, et celle de droite avec la Fastec IL5 avec une vitesse d’obturation de 60 microsecondes. Le ventilateur et la roue tournaient à la même vitesse dans les deux images, avec le même éclairage.
En comparant la performance des caméras rapides, nous sommes souvent confrontés à des matrices disparates de vitesses d’image et de résolutions. Ce processus peut être simplifié par la comparaison du débit de pixels. Pour une caméra rapide donnée, son débit de pixels maximal se verra à la résolution maximale. Le débit de pixels maximal est, tout simplement :
- La Résolution Maximale (résolution maximale verticale x résolution maximale horizontale) x fps max (@ résolution max)
Ainsi, si la résolution maximale est de 1280 x 1024 et que la vitesse d’image maximale à cette résolution est de 1000 fps, alors le débit de pixels maximal est de :
1280 x 1024 x 1000, soit 1 310 720 000 pixels/sec, soit 1,311Mp/sec.
Vitesse d’image, fréquence d’image, vitesse d’échantillonnage, vitesse de capture, vitesse d’enregistrement et vitesse de caméra sont autant de termes interchangeables. La vidéo au ralenti est créée lorsque la vitesse d’image d’un enregistrement, exprimée habituellement en images (« frames » en anglais) par seconde, ou « fps », est plus grande que la vitesse de lecture, également exprimée en fps. Par exemple, si une caméra enregistre à 300 fps et que le clip résultant est lu à 30 fps, il y aura un effet de ralenti de l’ordre de 10x. Pour donner un peu de perspective, les ralentis sportifs à la télévision sont lus à une vitesse entre 4x et 8x.
Les vitesses d’enregistrement sont des caractéristiques fondamentales de l’imagerie numérique à grande vitesse. Pour la plupart des utilisations techniques, la vitesse d’image idéale se détermine par le calcul de la vitesse de mouvement des objets dans le champ de vision. Pour ce faire, il faut considérer la vitesse absolue de l’objet par rapport au champ de vision. Celui-ci est imposé par le zoom, qui est fonction de la distance de l’objet, de la surface utile du capteur, et de la focale de l’objectif. La vitesse d’image nécessaire dépend aussi bien du zoom que de la vitesse de l’objet.
La configuration d’une prise de vue à grande vitesse, comme pour toute photographie, est un exercice d’équilibre entre les différentes options possibles. La fréquence d’image et la résolution constituent souvent le meilleur point de départ. Les caméras numériques rapides sont généralement capables de gérer des vitesses d’image élevées à des résolutions assez basses. Ensuite, il faut décider si l’on préfère une résolution plus forte et peut-être un champ de vision plus large avec une vitesse d’image moins rapide, ou bien une résolution inférieure et peut-être un champ de vision plus restreint, avec une vitesse d’image plus élevée.
Une autre option à prendre en compte est la durée d’enregistrement. Les caméras rapides peuvent produire énormément de données image en très peu de temps. Une vitesse d’image trop basse pourrait ne pas permettre de voir suffisamment de détail dans le comportement de l’objet, tandis qu’une vitesse d’image trop élevée pourrait nécessiter des besoins démesurés de stockage.
Les capteurs, ainsi parfois que les images, peuvent être qualifiés de 8-bits, 10-bits, 12-bits, etc. Ceci fait référence au nombre d’éléments binaires nécessaires pour exprimer des valeurs de pixel. Plus il y a de bits, plus grand est le nombre de valeurs, et plus grand le nombre de nuances qui peuvent être exprimées par chaque pixel.
Pour les caméras monochromes (nuances de gris) :
Un pixel 1- bit contient 21 (2) valeurs (noir et blanc)
Un pixel 2- bits comporte 22 (4) valeurs (noir, deux nuances intermédiaires, blanc)
Un pixel 3-bits contient 23 (8) valeurs
Un pixel 8-bits contient 28 (256) valeurs
Un pixel 10-bits contient 210 (1024) valeurs
Un pixel 12-bits contient 212 (4096) valeurs
Pour les caméras couleur, chaque pixel du capteur aura le même nombre de valeurs en ce qui concerne la profondeur de bits que les caméras monochromes. Cependant, un filtre de couleur simple, rouge, vert ou bleu, s’appliquera physiquement à chaque pixel également. Ainsi, un pixel 8-bits vert contiendra 256 valeurs pour le vert.
Les fichiers image RAW (non-compressées, non-interpolées) en provenance de caméras couleur conservent ce même nombre de valeurs par pixel.
Les images traitées RGB (red/green/blue = rouge/vert/bleu) issues de caméras couleur se voient attribuer 3 valeurs pour chaque pixel : rouge, vert et bleu, qui sont calculées (interpolées) en utilisant des valeurs des pixels environnants. Les images RGB ont donc un plus grand nombre de nuances pour chaque pixel en fonction de la profondeur de bits :
Un pixel 1- bit comprend 21 (2) valeurs “raw” et 23 (9) valeurs de couleurs
Un pixel 2- bits comprend 22 (4) valeurs “raw” et 43 (64) valeurs de couleurs
Un pixel 3- bits comprend 23 (8) valeurs “raw” et 83 (512) valeurs de couleurs
Un pixel 8-bits comprend 28 (256) valeurs “raw” et 2563 (16 777 216) valeurs de couleurs
Un pixel 10-bits comprend 210 (1024) valeurs “raw” et 10243 (1 073 741 824) valeurs de couleurs
Un pixel 12-bits comprend 212 (4096) valeurs “raw” et 40963 (68 719 476 736) valeurs de couleurs
La plupart des formats de fichier d’image et des dispositifs d’affichage sont limités à 8 bits / pixel.
L’intérêt d’enregistrer avec une profondeur de bits supérieur à 8 bits, est que les bits « en trop » peuvent s’avérer très utiles pour améliorer la qualité de l’image en post-production. Afin de tirer profit de profondeurs de bits plus conséquentes, les images doivent être stockées dans des formats de fichier qui les supportent, tels TIFF, RAW et DNG.
Le capteur est le cœur de toute caméra numérique. Parmi les éléments dont nous parlerons ici, beaucoup concernent les spécifications des capteurs, dont les plus importantes sont la Résolution et le Format.
Le capteur est un ensemble de pixels, organisés en colonnes et en lignes. Le nombre de pixels de chaque colonne indique la résolution horizontale du capteur, tandis que le nombre de pixels de chaque ligne indique la résolution verticale. L’unité de mesure qui sert habituellement à comparer la résolution d’un capteur est le mégapixel, ou MP. Un capteur qui comprend 1920 colonnes et 1080 lignes comportera un total de 2 073 600 pixels ; soit 2-mégapixels. 1920 x 1080 est une résolution fréquente dans le domaine télévisuel, et connue sous le terme ‘ full HD’. D’autres résolutions de capteur fréquentes sont : 1280 x 1024 (SXGA), ou 1,3MP, et 640 x 480 (VGA), ou 0,3MP. Des résolutions supérieures à la HD sont de plus en plus recherchées. Les caméras Fastec IL5 et TS5, par exemple, utilisent des capteurs de 5 mégapixels, avec 2560 colonnes et 2048 lignes.
Le format du capteur, ou format optique, est un terme qui sert souvent à décrire la taille physique d’un capteur. Beaucoup de caméras à grande vitesse utilisent des objectifs avec une monture C, initialement conçus pour le cinéma et les caméras de vidéo-surveillance. Des formats fréquents en monture C sont les 2/3-pouce, 1-pouce, et 4/3-pouce. La diagonale du capteur 2/3-pouce peut aller jusqu’à 11 mm, jusqu’à 16mm pour le capteur 1-pouce, et environ 23mm pour le 4/3-pouce. Des objectifs M43 (micro quatre-troisièmes), devenus très populaires grâce aux caméras réflexes sans miroir, ont également une diagonale d’environ 23mm.
Les capteurs plein format, qui sont relativement rare dans le monde de la grande vitesse, ont la même diagonale que le film 35mm, soit environ 42mm.
Un objectif qui fonctionne correctement sur une caméra avec un petit capteur, peut ne pas produire un cercle d’image suffisamment important pour fonctionner correctement sur une caméra dont le capteur est plus grand. La surface utilisée sur tel ou tel capteur varie aussi en fonction de la résolution. Un capteur qui permet une résolution de 1920 x 1080 en 2/3-pouces (diagonale de 11mm) n’utilisera qu’une diagonale de 8mm lorsqu’il enregistre à 1280 x 720.
Le terme pixel est une contraction des mots anglais ‘picture’ et ‘element’, et désigne l’élément le plus petit d’une image numérique, un point. Le terme peut décrire trois choses très différentes, mais liées :
- Un capteur CMOS grande vitesse se compose de millions de pixels sur un circuit intégré, ou puce. Chaque pixel comprend cinq à sept transistors minuscules, et est capable de convertir la lumière en une charge électrique qui est d’abord stockée, puis transmise à un convertisseur analogue/numérique, afin de produire une image numérique. Dans ce cas de figure, un ‘pixel’ est un élément physique d’un composant électronique.
- Une fois numérisées, les valeurs de pixel récupérées depuis le capteur peuvent être enregistrées dans la mémoire électronique ou sur un support de stockage de masse, pour faire partie d’un fichier d’image, ou bien transmises pour l’affichage, ou un mélange des deux. Les ‘pixels’ numérisés ont des valeurs numériques, les parties sombres de l’image ayant une valeur faible, et les parties claires une valeur élevée. Dans ce cas, un ‘pixel’ est une valeur numérique qui est stockée sur un support électronique.
- Enfin, les valeurs de pixel sont reconverties en lumière visible sous forme de pixels d’un écran d’ordinateur, d’un téléviseur, d’un téléphone, d’un casque VR, etc. Dans ce dernier cas, le pixel est un élément lumineux, ou une partie d’une configuration lumineuse, que ce soit une infime partie d’un écran d’ordinateur, ou une ampoule d’un grand écran de stade.
L’imagerie numérique à fréquence d’image élevée, obtenue avec des caméras rapides spécialisées comme celles de chez Fastec Imaging, répond aux deux définitions de la photographie rapide. Les images ci-dessous ont été réalisées avec une Fastec IL5 avec une vitesse d’obturation très rapide, permettant une série d’images nettes, telles des photographies réalisées avec un éclairage stroboscopique. Une fréquence d’images élevée permet d’enregistrer chaque moment important d’un événement. L’imagerie obtenue peut servir à la réalisation d’un clip captivant.
Des séquences comme celle-ci illustrent une utilisation très répandue des caméras grande vitesse : l’analyse d’événements qui sont trop rapides pour être perçus à l’œil nu.
L’effet de vidéo ralenti, lorsque la vitesse de visionnage d’une séquence est plus lente que la vitesse de capture, est un exemple de la deuxième définition de la photographie grande vitesse. Utilisé souvent pour la réalisation de films, c’est un outil cinématographique qui peut être subtil ou bien très marqué. Il peut servir à créer une ambiance, à appuyer un effet dramatique, ou à mettre en valeur la beauté d’un mouvement.
Dans des applications techniques (ligne de production haute cadence par exemple), la caméra rapide aide à voir les dysfonctionnements qui ne peuvent être vu à l’œil nu. Utilisé comme appareil de dépannage, elle permet d’identifier l’origine d’un incident mécanique inattendu, par exemple un bourrage de papier dans un enrouleur, ou une capsule manquée dans une chaîne d’embouteillage. La vidéo au ralenti sert aussi à analyser la locomotion animale, humaine ou robotique.
La photographie rapide peut être définie ainsi :
- Une prise d’image dont le but est de réduire le flou d’objets qui se déplacent plutôt rapidement, ou encore
- Une série d’images réalisées à une fréquence de capture élevée
Cette image d’une goutte d’eau correspond à la première définition. Dans cet exemple, une lumière stroboscopique a sans doute servi à figer le mouvement, et ainsi à capturer l’instant où la gouttelette d’eau forme une couronne.
L’image est intéressante autant pour son esthétique symétrique, que pour son illustration d’un comportement inattendu lors d’un événement banal.

La photographie haute vitesse – image figée de gouttes d’eau qui tombent